
AppliedStatistics & hypotheses
광고 포함
0+
다운로드

전체이용가
info
앱 정보
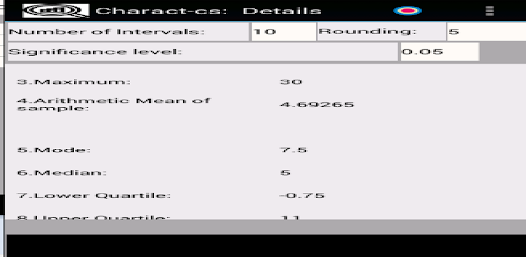
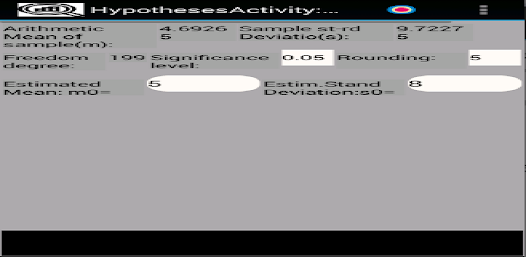
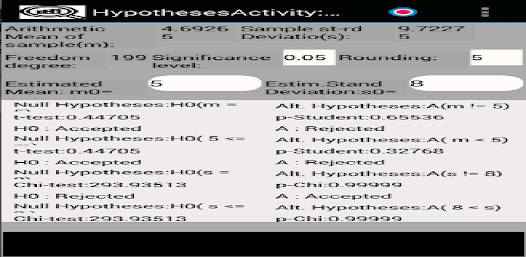
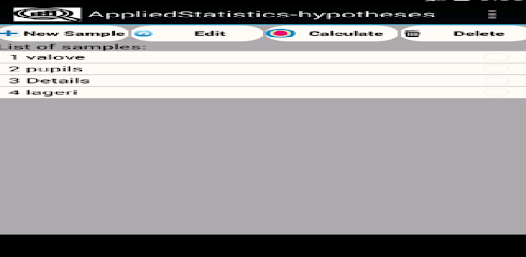
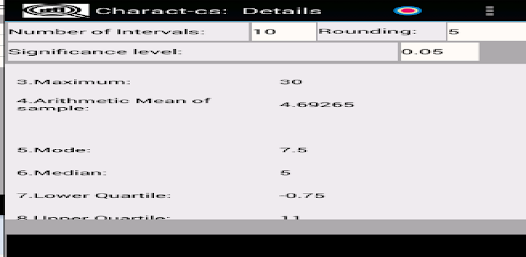
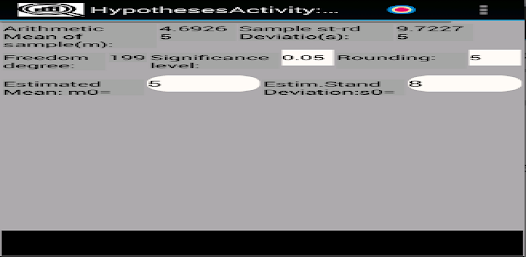
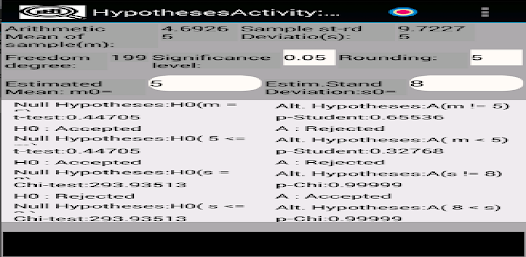
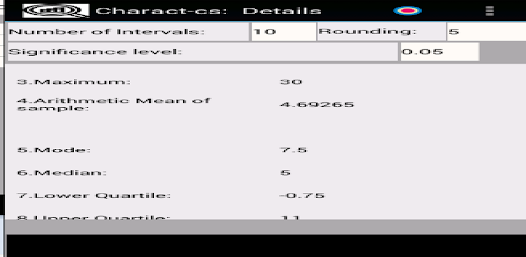
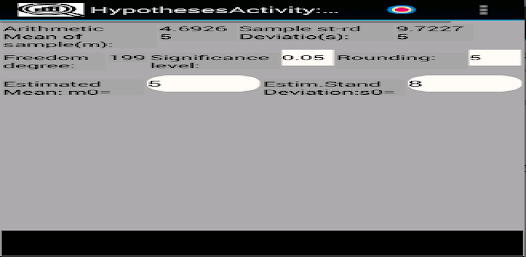
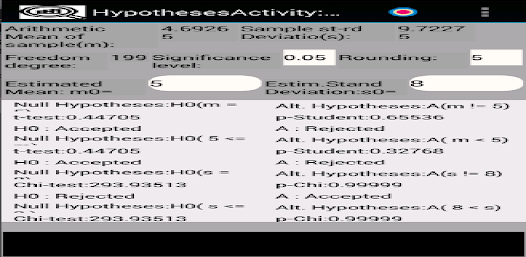
응용 프로그램은 확률 변수의 샘플을 저장(편집, 삭제, 이름 변경)하여 기본 통계적 특성을 다음과 같이 계산하도록 설계되었습니다. - 표준 편차; - 왜도 및 첨도; - 평균값의 신뢰구간을 계산하기 위해; - 분산 및 표준 편차; - 표본이 Pearson의 기준을 사용하여 정규 분포 또는 균일 분포 확률 변수에서 추출되었는지 확인합니다. - 표본이 Kolmogorov-Smirnov 기준을 사용하여 정규 분포의 균일하고 기하급수적으로 분포된 랜덤 변수인지 확인합니다. - 그리고 0 왜도 및 첨도; - 평균 및 표준편차와 관련된 가설의 기능 테스트 및 기타.
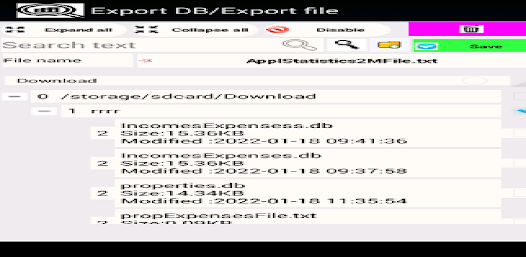
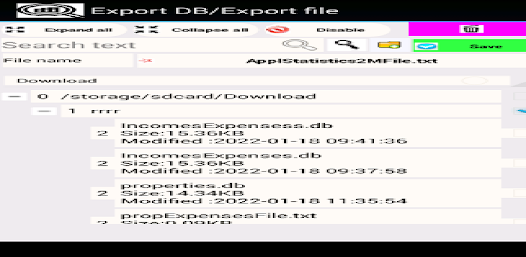
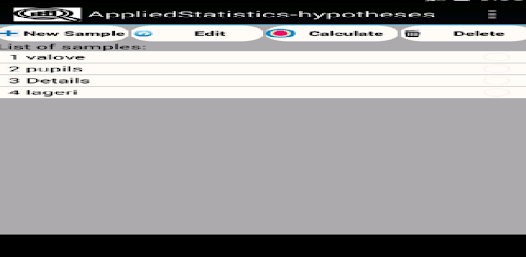
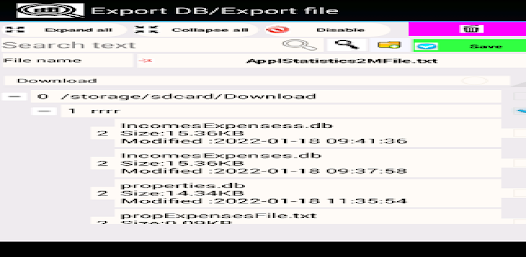
샘플, 처리 결과 및 히스토그램을 데이터베이스(Sqlit)에 저장할 수 있습니다. 이러한 데이터가 있는 테이블은 예를 들어 Sqlit 브라우저를 사용하여 인쇄를 위해 내보낼 수 있습니다. 응용 프로그램을 처음 부팅할 때 부팅 활동 메뉴에서 "Init DB"(DB 초기화) 기능을 수행합니다. 이 기능을 구현하면 일부 샘플 목록이 로드됩니다.
샘플, 처리 결과 및 히스토그램을 데이터베이스(Sqlit)에 저장할 수 있습니다. 이러한 데이터가 있는 테이블은 예를 들어 Sqlit 브라우저를 사용하여 인쇄를 위해 내보낼 수 있습니다. 응용 프로그램을 처음 부팅할 때 부팅 활동 메뉴에서 "Init DB"(DB 초기화) 기능을 수행합니다. 이 기능을 구현하면 일부 샘플 목록이 로드됩니다.
업데이트 날짜


앱 지원
개발자 소개
Ivan Zdravkov Gabrovski
ivan_gabrovsky@yahoo.com
жк.Младост 1 47 вх 1 ет. 16 ап. 122
1784 общ. Столична гр София
Bulgaria





